A los que siguen este blog…
Como se puede apreciar, he reconvertido el blog a una web de carácter personal. Es una evolución del todo punto lógica, que espero sea positiva.
En su origen, el blog era un complemento a mis investigaciones y desarrollos en Gestión de la calidad, tanto como formador como asesor de empresas (Editoriales, Imprentas e Instituciones de Enseñanza). Parece ser que feliz (y raramente) acerté al elegir a mi proveedor de este tipo de servicios ya que opté en su momento por WordPress.
Actualmente, WordPress es uno de los grandes en el terreno de juego web, con un alto grado de penetración en las empresas, y como quiera que lo he venido utilizando desde hace años, aunque sin profundizar en sus muchas posibilidades, estoy en posición de sacar partido de ese uso continuado.
El blog, que en su momento denominé «Calidad gráfica», y que viene teniendo unos cuantos seguidores (aunque no he hecho ningún esfuerzo de posicionamiento) ha venido sufriendo mi propia evolución (ya va para 5 años): aun siguiendo centrado en Calidad, en los últimos tiempos he venido publicando artículos relacionados con el mundo web, ya que es la evolución lógica (y ya obligada) de la Galaxia Comunicación (de ahí el título).
Otro hecho a destacar es que la construcción de la página web me ha hecho bucear en proyectos en los cuales he participado y que ahora pueden ponerse a disposición de un público más amplio si es de su interés (veáse la página de Diseño-Ilustración).
Esto es, he decidido abrir el blog a todo lo que me merezca interés u que crea interesante compartir, sin centrarme en un tema concreto. Nos dispersamos, lo se, por lo que puede que algún seguidor no le agrade, pero ganamos en matices.
Las primeras temporadas del blog dedicadas a la Gestión y Control de la Calidad están publicadas en Isuu y sus enlaces se hallan en esta web en Documentos. La quinta temporada he decidido no publicarla ya que en ella se introducen aspectos no tan centrados en la Calidad, derivando hacia al entorno web, no obstante se pueden consultar en esta propia web, lógicamente. Un saludo.

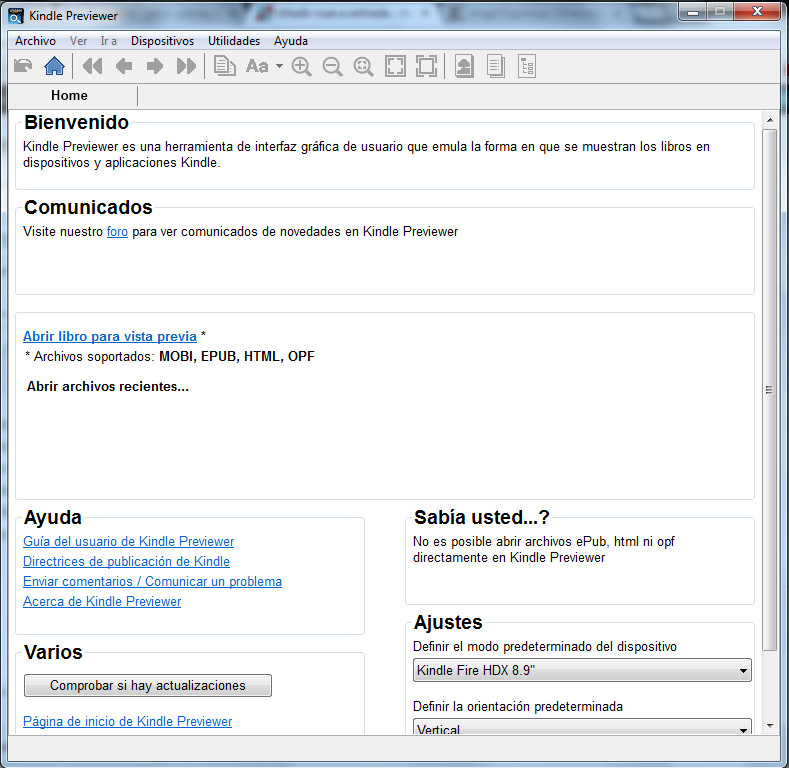 Kindle Previewer, herramienta que se instala en el PC y permite previsualizar el libro electrónico tal y como lo veríamos en el Kindle. Sirve para realizar pruebas previas antes de publicar en este formato.
Kindle Previewer, herramienta que se instala en el PC y permite previsualizar el libro electrónico tal y como lo veríamos en el Kindle. Sirve para realizar pruebas previas antes de publicar en este formato.